
Understand Ownership in Rust
In this lesson, we will be exploring some low-level concepts and understanding how Ownership works.


GitHub repo with all the code
https://github.com/codetit4n/rust-school
For this lesson: https://github.com/codetit4n/rust-school/tree/main/lesson-6
Make sure to star/fork/watch it on GitHub.
Memory Safety
Rust is a memory-safe language. This means Rust can prevent programmers from introducing some type of bugs related to how memory is used. Since these bugs are often security issues, memory-safe languages are more secure than languages that are not memory safe.
Should I care about memory safety?
Well, this depends on your use case. In some cases, you need memory safety in others not so much. As an engineer, you should be able to make efficient choices and at the same time, avoid overengineering things. So, pick carefully.
One analogy is that: The world doesn't care if you have the fastest to-do list app, with memory safety and everything.
Memory safety and Garbage collectors
Automatic memory management in the form of garbage collection is the most common technique for preventing some of the memory safety problems. So, a lot of languages have these garbage collectors. Which are used to automatically free up memory space that is allocated recently but is no longer needed.
Rust and Memory Safety
When building critical infrastructure like low-level systems, blockchains, smart contracts, etc you need memory safety. This is where Rust shines the most. Rust provides memory safety guarantees without needing a garbage collector. This is done because of Ownership. So it’s important to understand how ownership works.
The Stack and the Heap
Both the stack and the heap are parts of memory available to your code to use at runtime, but they are structured in different ways.
Stack
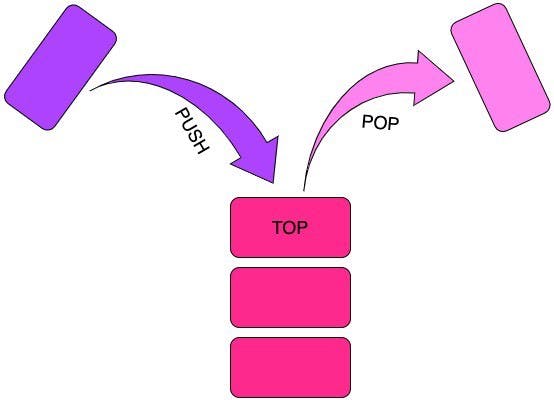
Stack uses what we call LIFO (Last In First Out) approach. This means it will store values in the order it gets them and removes the values in the opposite order.
The process of adding something to the stack is called PUSH and the process of removing something from the top of the stack is called POP. Since both of these operations are done on the top of the stack we have a special pointer that always points to the top called TOP. All data stored on the stack must have a known, fixed size.
Heap
The heap is less organized: when you put data on the heap, you request a certain amount of space. The memory allocator finds an empty spot in the heap that is big enough, marks it as being in use, and returns a pointer, which is the address of that location. You may have heard of this if you are familiar with pointers in C++.
The process of allocating memory on the heap is sometimes abbreviated as just allocating (pushing values onto the stack is not considered allocating). Because the pointer to the heap is a known, fixed size, you can store the pointer on the stack, but when you want the actual data, you must follow the pointer. This must be sounding complicated, so here is an analogy from the rust book:
Think of being seated at a restaurant. When you enter, you state the number of people in your group, and the host finds an empty table that fits everyone and leads you there. If someone in your group comes late, they can ask where you’ve been seated to find you.
Stack vs Heap
Now, in one case we are just pushing data to the TOP of the stack, and in the other case, we are first finding a space in the memory and then allocating it accordingly(heap). Which one do you think is faster? The stack of course.
Comparatively, allocating space on the heap requires more work because the allocator must first find a big enough space to hold the data and then perform bookkeeping to prepare for the next allocation.
Accessing data in the heap is slower than accessing data on the stack because you have to follow a pointer to get there. Continuing the analogy:
Consider a server at a restaurant taking orders from many tables. It’s most efficient to get all the orders at one table before moving on to the next table. Taking an order from table A, then an order from table B, then one from A again, and then one from B again would be a much slower process. By the same token, a processor can do its job better if it works on data that’s close to other data (as it is on the stack) rather than farther away (as it can be on the heap).
Stacks and Heaps in Rust
When your code calls a function, the values passed into the function (including, potentially, pointers to data on the heap) and the function’s local variables get pushed onto the stack. When the function is over, those values get popped off the stack.
Ownership
Ownership is a set of rules that govern how a Rust program manages memory. All programs have to manage the way they use a computer’s memory while running. So, how do they do it? They use these 3 approaches:
Using garbage collectors. Discussed earlier.
In some languages, programmers must explicitly allocate and free the memory.
Rust uses a third approach called ownership.
Memory is managed through a system of ownership with a set of rules that the compiler checks. If any of the rules are violated, the program won’t compile. None of the features of ownership will slow down your program while it’s running.
Ownership Rules
Always keep these ownership rules in mind while working with Rust:
Each value in Rust has an owner.
There can only be one owner at a time.
When the owner goes out of scope, the value will be dropped.
The String Type
To illustrate the rules of ownership, we need a data type that is more complex than those we covered in earlier articles of this series. The data types we looked at earlier were stored on a stack. But we want to look at data that is stored on the heap and explore how Rust knows when to clean up that data. So, we will learn about String here.
String Literals:
Simple hardcoded strings are called string literals. Example:
let s = "Hello";
These are not suitable for all situations. Few things to note:
These are immutable. Which means they are not suitable for all situations.
Not every string value can be known in advance when writing code. Example: User inputs.
String type:
For situations where string literals are not enough rust has the string type,
String.This type manages data allocated on the heap and as such is able to store an amount of text that is unknown to us at compile time.
You can create a
Stringfrom a string literal like this:let s1 = String::from("Hello there!");NOTE:
::operator allows us to namespace this particularfromfunction under theStringtype. We'll learn about namespaces in later articles of this series.This kind of string can be mutated. Which means it can be updated like this:
let mut s2 = String::from("Hello"); s2.push_str(", world!"); println!("{s2}")Here, push_str() appends a literal to a String. Output:
But, why is that
Stringcan be mutated but literals cannot?The difference is in how these two types deal with memory.
Memory and Allocation
With the String type, in order to support a mutable, growable piece of text, we need to allocate an amount of memory on the heap, unknown at compile time, to hold the contents. This means:
The memory must be requested from the memory allocator at runtime.
We need a way of returning this memory to the allocator when we’re done with our
String.
That first part is done by us: when we call String::from, its implementation requests the memory it needs.
For the second part in Rust: the memory is automatically returned once the variable that owns it goes out of scope. This is done differently in many other programming languages(with garbage collectors, etc).
Consider the code:
{
let s = String::from("Hello");//s is valid from this point
//work with s
} //s no longer valid because the scope is over
Here, as the s goes out of scope, Rust automatically calls a special function called drop which returns the allocated memory on the heap back.
This may look simple now, but it is amazing how many complex scenarios this can handle.
Understanding allocation in different scenarios
Consider the code:
let x = 6;
let y = x;
Here, first, the value 6 is bind to the variable x and then a copy of the same will be bind to y . This is indeed what is happening, because integers are simple values with a known, fixed size, and these two 6 values are pushed onto the stack.
This was a simple example of fixed-sized variables. But things are different when we use heaps. Consider the code:
let str1 = String::from("Hello");
let str2 = str1;
println!("{str1}, world!");
Here, first, we created a str1 variable using the String type. Let's see what happens here under the hood:
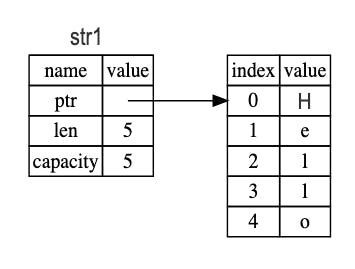
On the right side, we have the heap. The str1 contains 3 things:
ptr: pointer to the memory that holds the contents of the string.
len: The length is how much memory, in bytes, the contents of the
Stringare currently using.capacity: The capacity is the total amount of memory, in bytes, that the
Stringhas received from the allocator.
The difference between length and capacity matters, but not in this context, so for now, it’s fine to ignore the capacity.
Now, when we do:
let str2 = str1;
Here, is what is happening under the hood:
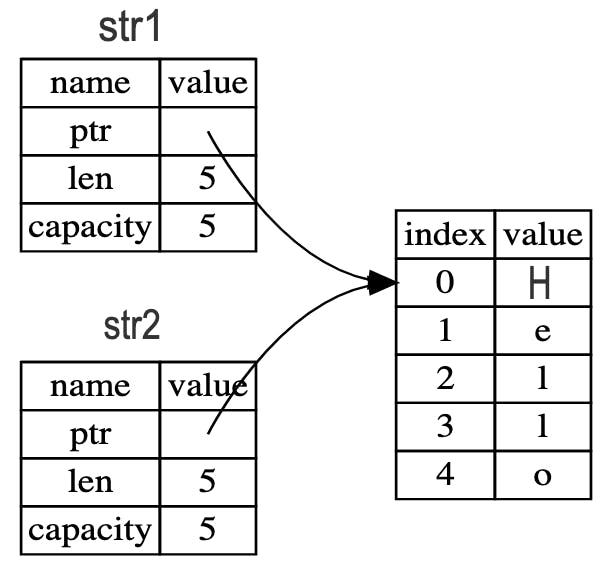
Here, note that the data in the heap(right side) is not being copied. Only the ptr, len, capacity is being copied to str2.
This shows that we just point a new String to the same heap memory location. This is different from our integer example.
This brings a problem:
Earlier, we said that when a variable goes out of scope, Rust automatically calls the drop function and cleans up the heap memory for that variable. Since, here both str1 and str2 are pointing to the same memory location, when str2 and str1 go out of scope, they will both try to free the same memory. This is called the double free error and is one of the memory safety bugs. It can lead to memory corruption, which can potentially lead to security vulnerabilities.
Rust deals with this issue using something called move.
Move
So, what happens when we do let str2 = str1;?
To ensure memory safety, after the above statement, Rust considers str1 as no longer valid. Which means str1 is moved into str2 .
So, now as the str1 is no longer valid there is no double free error to deal with. With only str2 valid, when it goes out of scope it alone will free the memory, and we’re done.
So, if I try to run this code:
let str1 = String::from("Hello");
let str2 = str1;
println!("{str1}, world!");
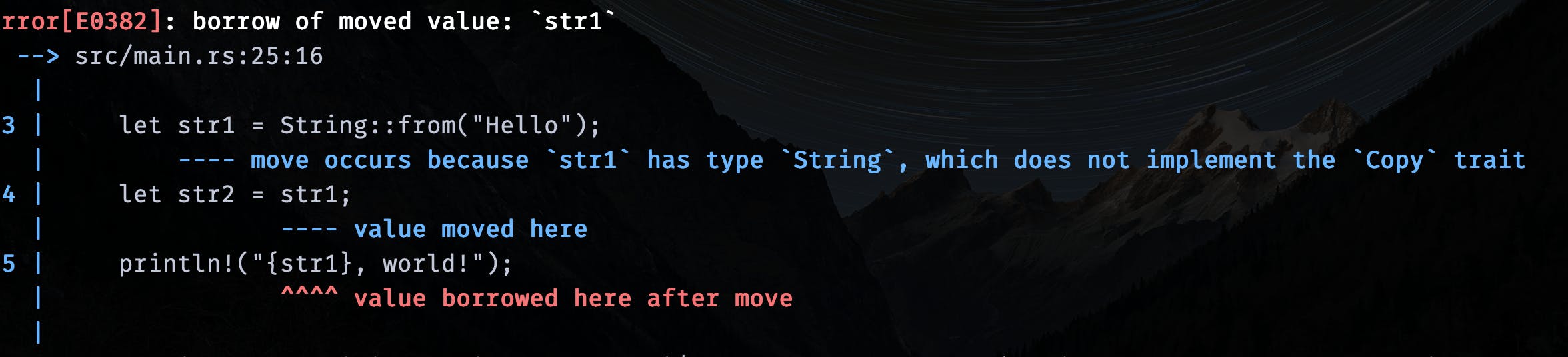
Here, you can see the Rust compiler explains it very well. When we try to access the str1 in println!("{str1}, world!"); it is no longer available(moved).
Sidenote from the Book: If you’ve heard the terms shallow copy and deep copy while working with other languages, the concept of copying the pointer, length, and capacity without copying the data probably sounds like making a shallow copy. But because Rust also invalidates the first variable, instead of being called a shallow copy, it’s known as a move. In addition, there’s a design choice that’s implied by this: Rust will never automatically create “deep” copies of your data. Therefore, any automatic copying can be assumed to be inexpensive in terms of runtime performance.
Clone
Now, if we do want to deeply copy the heap data of the String, not just the stack data, we can use this method called clone. Example:
let str3 = String::from("Hi");
let str4 = str3.clone(); //clone
println!("str3: {str3} | str4: {str4}");
Here using the clone() method on the String variable we can deeply copy the whole heap data of str3 into str4 .
Copy: For stack-only data
Rust has a special annotation called the Copy trait that we can place on types that are stored on the stack, as integers are. If a type implements the Copy trait, variables that use it do not move, but rather are trivially copied, making them still valid after assignment to another variable. Rust won’t let us annotate a type with Copy if the type, or any of its parts, has implemented the Drop trait.
Now, you know why when we were using integers (fixed-sized), the move problem was not there. Because they implement this Copy trait.
Here are some of the types that implement Copy:
All the integer types, such as
u32.The Boolean type,
bool, with valuestrueandfalse.All the floating-point types, such as
f64.The character type,
char.Tuples, if they only contain types that also implement
Copy. For example,(i32, i32)implementsCopy, but(i32, String)does not.
Ownership and Functions
The mechanics of passing a value to a function are similar to those when assigning a value to a variable. Passing a variable to a function will move or copy, just as the assignment does.
Consider the code:
fn main(){
let num = 4;
print_num(num);
print_num(num);
}
fn print_num(some_integer: i32){
println!("{some_integer}");
}
Q: Will this throw an error?
A: No. Because when we first call the print_num(num); It is true that the value is moved into the print_num function. Which means it should not allow the second print_num(num); function call. But since num is of the type i32 which implements the Copy trait, it will not throw an error.
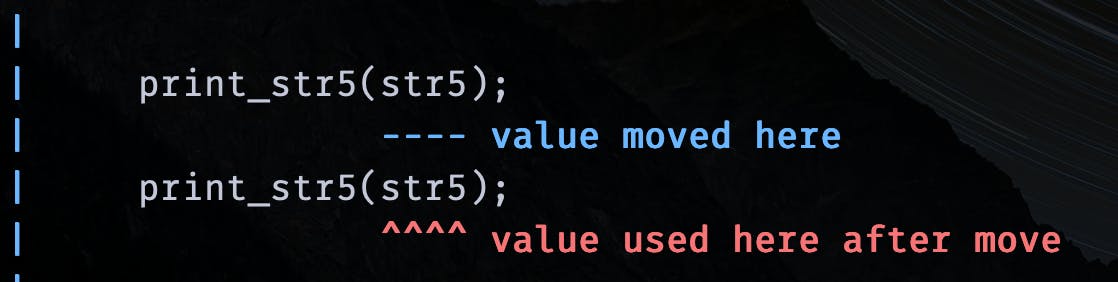
Now, consider this code:
fn main(){
let str5 = String::from("hey!");
print_str5(str5);
print_str5(str5);
}
fn print_str5(some_string: String){
println!("{some_string}");
}
Here, we are trying to do something similar with String type. But because of move it will not allow the second print_str5(str5); function call.
Note: By moving some variable to a function or a variable, Rust is basically transferring its ownership to the said function or variable.
Return Values and Ownership
Returning some values from functions can also transfer ownership. Consider the code:
fn main(){
let returned_value = give_ownership();
}
fn give_ownership()->String{
let some_string = String::from("hey!");
some_string
}
Here, give_ownership() will move its returned value into the function that calls it (main in this case). So, it will be dropped when the returned_value will go out of scope(end of main).
Similarly for this code:
fn main(){
let to_pass = String::from("hello");
let got = takes_and_gives_back(to_pass);
}
fn takes_and_gives_back(a_string: String) -> String {
a_string
}
Here, the takes_and_gives_back(a_string: String) function takes a String and returns one. When we call the takes_and_gives_back(to_pass) it moves the to_pass to the takes_and_gives_back function and then moves it back to the original function(main).
The ownership of a variable follows the same pattern every time:
Assigning a value to another variable moves it.
When a variable that includes data on the heap goes out of scope, the value will be cleaned up by
dropunless ownership of the data has been moved to another variable.
Now, this might seem very tedious: taking ownership and then returning ownership with every function. But Rust provides a way to let us pass a value to a function without giving its ownership to that function, which is called references.
We will look into references in the next article of the series.